2018-09-28 作者: Fisherworks
Waiting for the final season soooooo long time, and it exactly shows the original story telling skills of Telltale.
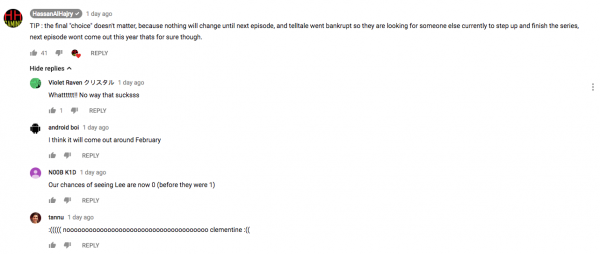
After the video walkthrough, the author commented that Telltale had went bankrupt and this season might not be accomplished this year, or worse… maybe something like… never.
A total disaster… ehh… not easy to accept that, been following this storyline from 2012 to 2018, especially with the recent E3 videos.
If there could be some way to donate a little (I suppose it was too late to buy the game), I guess I could put like fifty or maybe hundred bucks to prove that I really got a lot from this story series.
To me, personally, the best was season #1, then #2 and #4, the #3… nothing left in mind but that was ok anyway, good, still.



My favorite “no-comment” video author, Hassan, chose to let Clem kiss Louis – that’s not typical him, I mean not his style on choice.
But after I saw his comment – I realize this episode might be the last one.
At the end of this ep, Louis was caught and took away with intruders, which means we probably never know any of the possibilities between Clem and him – that would be the reason why Hassan, the video author, choose the kiss, instead of hiding the feeling to each other during this apocalypse.


Wrecking the gorgeous right in the face, that’s called TRAGEDY.
悲剧就是把美撕碎了给人看。
完整阅读本篇»















 京公网安备 11011502004657号
京公网安备 11011502004657号